The members of OpenAI’s Superalignment team were diligently working on the challenge of controlling artificial intelligence (AI) that is smarter than humans. This team aimed to develop and fine-tune an OpenAI superhuman AI that would revolutionize various industries. However, amidst their efforts, unexpected events unfolded. Investors, who had put their trust and resources into OpenAI, were now facing the risk of losing everything following Sam Altman’s abrupt termination from the business. Despite this setback, Altman, being a visionary and determined leader, was already hatching a plan to find his way back and contribute to the ongoing mission of OpenAI in creating an OpenAI superhuman AI.
Or, anyhow, that’s the story they want to tell.
I spoke with Colin Burns, Pavel Izmailov, and Leopold Aschenbrenner, three members of the Superalignment team, over the phone this week when they were attending NeurIPS, the yearly machine learning conference, in New Orleans. We discussed OpenAI’s most recent research on making sure AI systems operate as intended.
To create methods for directing, controlling, and governing “superintelligent” AI systems—that is, hypothetical computers with intelligence much beyond that of humans—OpenAI established the Superalignment team in July.
“We can essentially align models that are dumber than us today, or at most around human-level,” stated Burns. “How do we even align a model that is smarter than us? It’s much, much less obvious.”
Ilya Sutskever, the principal scientist and co-founder of OpenAI, spearheads the Superalignment initiative. While this didn’t raise any red flags in July, it does now, given that Sutskever was one of the people who first advocated for Altman’s termination. According to OpenAI’s PR, Sutskever is still leading the Superalignment team as of right now, despite some reports suggesting that he is in a “state of limbo” after Altman’s return.
Within the community of AI research, superalignment is a somewhat contentious topic. The subfield is premature, according to some, and a red herring, according to others.
Even though Altman has compared OpenAI to the Manhattan Project and even assembled a team to investigate AI models to guard against “catastrophic risks,” such as chemical and nuclear threats, some experts believe there is little evidence to support the startup’s claims that its technology will ever be able to outsmart humans or end the world. These experts further add that claims of impending superintelligence are merely a calculated diversion from the urgent regulatory concerns surrounding AI, such as algorithmic bias and the technology’s propensity for toxicity.
In any case, Suksever seems genuinely convinced that artificial intelligence (AI)—not OpenAI specifically, but a version of it—may present a threat to human existence in the future. To show his dedication to stopping AI damage from coming to humans, he allegedly went so far as to commission and burn a wooden effigy during a business offsite. He also commands a sizable portion of OpenAI’s compute—20% of its current computer chips—for the Superalignment team’s research.
Aschenbrenner declared, “I can assure you that AI progress is not slowing down. It has been extraordinarily rapid recently.” “I believe that human-level systems will be reached quite soon, but we won’t stop there—we’ll continue to superhuman systems… Thus, how can we make superhuman AI systems safe and aligned? In actuality, it affects all of humanity and is arguably the most significant unresolved technical issue of our day.
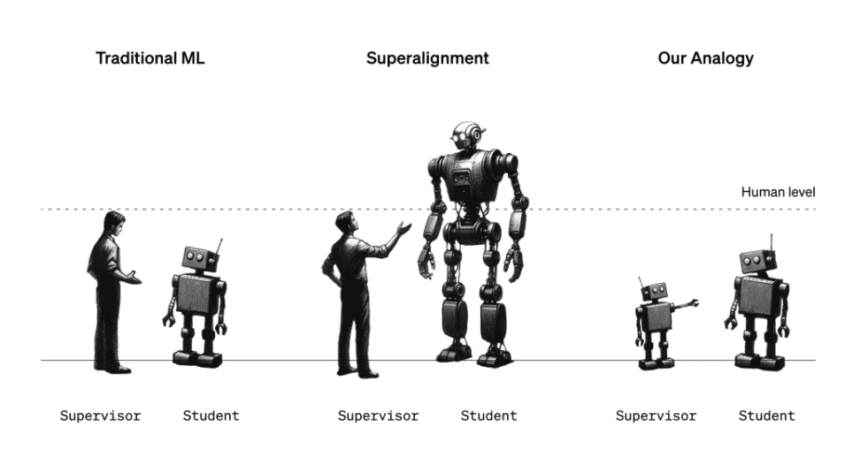
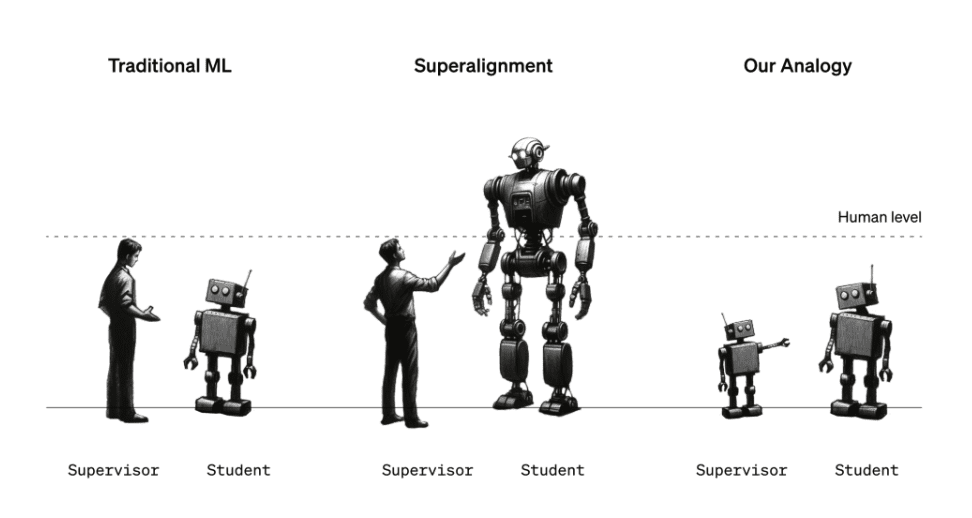
The Superalignment team is working on developing governance and control frameworks that could be useful for superpower AI systems in the future. It’s not an easy assignment given the intense dispute surrounding the notion of “superintelligence” and whether or not a certain AI system has attained it. However, the team’s current strategy is directing a more sophisticated, advanced model (GPT-4) in the right directions and away from the wrong ones using a weaker, less sophisticated AI model (e.g., GPT-2).
Telling a model what to do and making sure it does it are major goals, according to Burns. “How can we train a model to adhere to guidelines and to provide assistance only with verifiable information rather than fabrications? How can we get a model to inform us whether the code it produces is safe or behaves outrageously? These are the kinds of goals we hope to accomplish with our study.
You might ask, “But wait, what’s the connection between stopping humanity-threatening AI and AI that guides AI?” It’s an analogy, really, with the strong model standing in for extremely sophisticated artificial intelligence and the weak model serving as a substitute for human supervisors. The Superalignment team claims that the configuration is effective for verifying superalignment hypotheses since the weak model is unable to fully “understand” the subtleties and intricacies of the strong model, much like humans might not be able to comprehend a superintelligent AI system.
Izmailov clarified, “You can imagine a sixth-grade student attempting to supervise a college student.” “Suppose the sixth-grader is attempting to explain to the college student a problem that he can sort of solve… It is hoped that the college student will get the main idea and be able to complete the assignment more accurately than the sixth-grader supervisor, notwithstanding the possibility of errors in specifics.
Under the arrangement adopted by the Superalignment team, a weak model that has been tuned for a specific task produces labels that are used to “communicate” to the strong model the generalities of that task. The team discovered that even in cases when the weak model’s labels contain biases and errors, the strong model can nevertheless generalize in a way that is roughly in line with the weak model’s goal given these labels.
According to the team, the weak-strong model method may potentially result in advancements in the field of hallucinations.
“Because the model knows whether what it’s saying is fact or fiction internally, hallucinations are pretty interesting,” Aschenbrenner added. However, the way these models are taught now, human supervisors give them “thumbs up” or “thumbs down” according to what they say. Thus, on occasion, people unintentionally encourage the model to say untrue things or that it is ignorant of, and so on. If our research is successful, we should create methods for essentially calling upon the knowledge of the model. We might then use this summoning to determine if an object is real, which would help lessen hallucinations.
However, the parallel is not flawless. OpenAI thus seeks to crowdsource concepts.
To do this, OpenAI is introducing a $10 million grant program, with portions designated for graduate students, individual researchers, nonprofit organizations, and academic labs. The initiative’s goal is to encourage technical research on superintelligent alignment. In early 2025, OpenAI intends to hold an academic conference on superalignment, during which it will disseminate and endorse the work of the finalists for the superalignment prize.
Strangely, former Google chairman and CEO Eric Schmidt will contribute some funds for the grant. As a devoted follower of Altman, Schmidt is quickly emerging as a poster child for AI doomerism, claiming that policymakers aren’t doing enough to prepare for the impending arrival of harmful AI systems. It’s not necessarily because of charity, as reports in Protocol and Wired point out; Schmidt is an active AI investor and would profit handsomely on a commercial basis if the U.S. government adopted his suggested plan to support AI research.
From a cynical perspective, then, the donation could be seen as virtue signaling. With an estimated net worth of $24 billion, Schmidt has invested hundreds of millions of dollars in other AI projects and funds that are noticeably less ethically conscious than his own.
Naturally, Schmidt disputes that this is the case.
In an email statement, he said, “AI and other emerging technologies are reshaping our economy and society.” “They must be in line with human values, and I am honored to endorse OpenAI’s new funding to responsibly develop and manage AI for the good of society.”
The question of whether OpenAI’s superalignment research and the research it is asking the community to contribute to its upcoming conference will be made available for anybody to use as they see appropriate is raised by the involvement of a figure with such obvious commercial objectives.
The Superalignment team reassured me that OpenAI’s research, including code, and other people’s work on superalignment-related projects who win OpenAI funding and prizes will be made available to the public. We’ll hold the business accountable.
Aschenbrenner stated, “Part of our mission is to contribute not just to the safety of our models, but also to the safety of other labs’ models and advanced AI in general.” It is fundamental to our goal of developing [AI] in a safe manner for the good of all people. Furthermore, we believe that conducting this research is crucial to ensuring its safety and benefits.







{kind=link}